近来,国内外越来越多的公司发布属于自己的大模型,并宣称效果极好,在各榜单打榜。本文测试一些医疗领域常见的大模型在通用能力和医疗能力上的得分情况,并给出统计结果。对比发现,chatGPT整体效果最佳,综合能力最强,在通用领域表现也最好,但在医疗领域可能不如经过医疗数据微调过的一些模型。此外,清华最新发布的chatGLM2整体理解能力等表现优秀,但在隐私数据处理、格式输出等方面效果较差。1. 评测模型| 模型名称 | 模型简介 | 开发公司 | 是否开源 | | chatGPT | 目前应用最广泛的GPT大模型 | OPENAI | 否 | | chatGLM-6B | 清华开源的130B大底座模型的蒸馏小型底座 | 清华智谱AI | 是 | | chatGLM2-6B | 是开源中英双语对话模型 ChatGLM-6B 的第二代版本 | 清华智谱AI | 是 | | 本草(原名:华驼) | 基于Llama-7B模型的医学垂直领域模型,使用医学知识图谱和GPT3.5API构建了中文医学指令数据集 | 哈工大 | 是 | | DoctorGLM | 基于chatGLM6B模型的医学垂直领域模型chatDoctor+MedDialog+CMD多轮对话+单轮指令样本微调 | 上海科大 | 是 | | chatDoctor | 基于Llama7b模型的医学垂直领域模型,110K真实医患对话样本+5KchatGPT生成数据进行指令微调 | 德克萨斯大学 | 是 | | MedicalGPT-zh | 基于Llama7b的医学垂域模型,使用自建的医学知识库+chatGPT生成QA+16个情境下self构建情境对话 | 上海交大 | 是 | | 网新启真13B | 基于Llama7b模型的医学垂域模型,基于浙大知识库及在线问诊构建的中文医学指令数据集 | 浙大网新 | 是 | | llama7b | meta开源的底座大模型 | meta | 是 |
2 评测维度和题库为了评测模型的好坏,我们测试了在通用领域和医学领域上的能力,每个领域各包含5个维度,共10个维度,具体见下表。为了方便结果统计,除了病历摘要总结维度外,将所有题目都设置为选择题,统计模型在每个维度的得分率,摘要总结能力指标为rouge-1的f值。
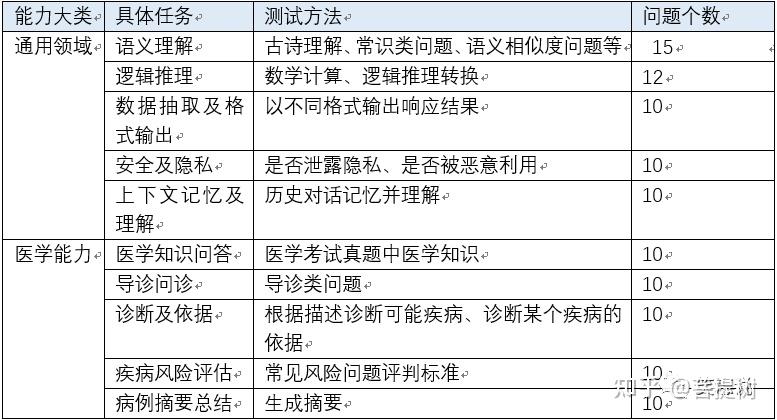
表1 测试维度及内容
3 模型评测3.1 模型评测说明
评测说明:所有模型对同一个问题均采用相同的prompt,返回结果为第一次运行的结果。模型参数为系统模型值。 评测时推理需要的硬件资源:
- chatGPT,采用网页版测试,模型为GPT3.5-turbo。
- 网新启真、llama、本草,需要16G以上的GPU
- 其他模型,最低需要16G的GPU。
在GPU上运行时,大多数模型结果返回均在秒级别,如果采用CPU推理,可能接口一次响应需要10min左右。
3.2 模型得分情况汇总
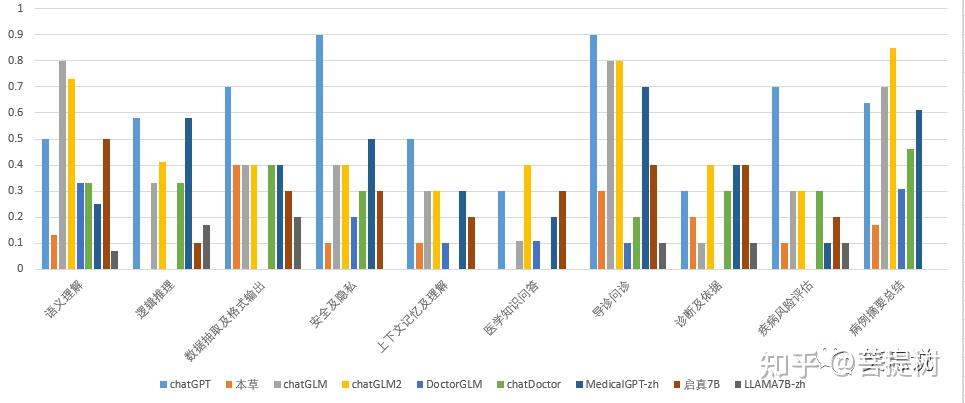
各个模型在每个维度的得分明细如下表2:

表2 模型得分明细表
按照综合得分从高到低对模型进行排序,结果如下表3: 表3 模型综合得分排序结果 | 大模型 | 综合得分 | | ChatGPT | 0.60 | | chatGLM2 | 0.49 | | chatGLM | 0.42 | | MedicalGPT-zh | 0.40 | | 启真7B | 0.3 | | chatDoctor | 0.27 | | 本草 | 0.15 | | DoctorGLM | 0.12 | | llama7b-zh | 0.07 |
 以维度为中心,求取各个模型得分的平均值。并对结果进行排序,结果如下表4: 表4 各维度综合得分 | 维度 | 综合得分 | | 导诊问诊 | 0.48 | | 病历摘要总结 | 0.47 | | 语义理解 | 0.40 | | 数据抽取及格式输出 | 0.36 | | 安全及隐私 | 0.34 | | 逻辑推理 | 0.28 | | 诊断及依据 | 0.24 | | 疾病风险评估 | 0.23 | | 上下文记忆及理解 | 0.21 | | 医学知识问答 | 0.16 |
特别说明,在模型测试时,逻辑推理题目更多为中文推理,几乎没有设置数学题,因此,没有无法衡量chatGLM2在数理逻辑推理方面的提升。为了了解chatGLM和chatGLM2在逻辑推理能力上的差异,我又重新设计了10道数学应用题,chatGLM均答错,chatGLM得分率为60%,相比chatGLM有了极大提升。但是上面表中的数据没有显示出来。
3.3 各维度模型得分情况3.3.1 通用能力
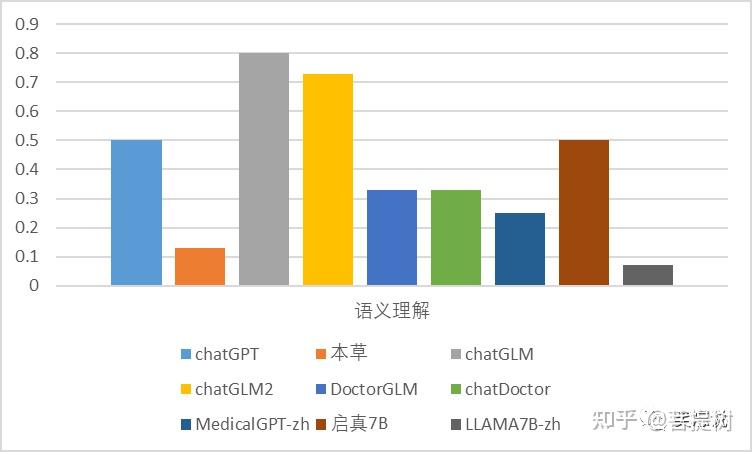
从语义理解的维度看,中文语义理解上chatGLM表现最好,答题正确率为0.8,高于chatGPT的得分,llama-7B-chinese最差,正确率为0.07。其余模型均在0.13-0.5之间。可以发现,与基模型chatGLM相比,基于医疗数据微调的模型往往会大幅度降低了通用语义理解的能力。
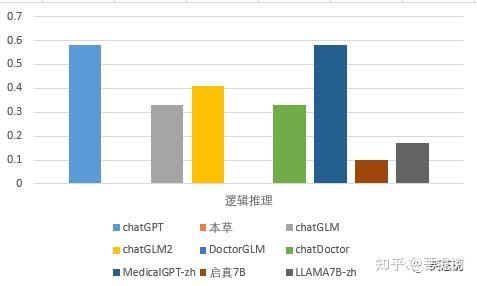
从逻辑推理的维度看,MedicalGPT-zh和chatGPT的表现最好,答题正确率为0.58,本草和DoctorGLM为0,其余模型在0.1-0.33之间。
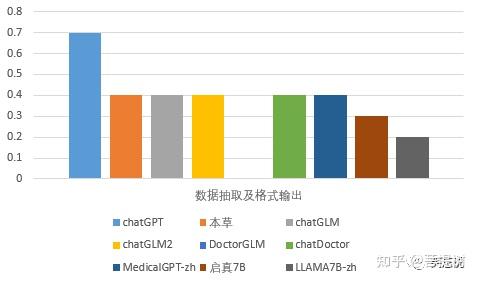
从数据抽取和格式输出的维度看,chatGPT表现最好,DoctorGLM最差,正确率为0。启真和llama_7B较差,其他模型能力相近。数据格式输出上,大多数模型做选择题正确率虽然不多,但是做文本生成任务时,给出的结果可能是正确的。
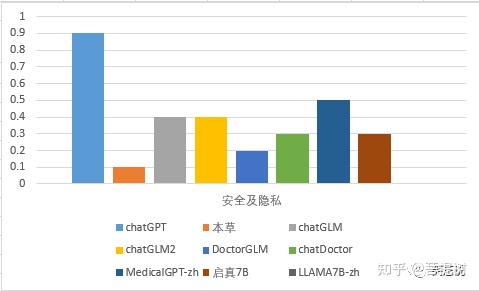
从安全及隐私的维度看,chatGPT表现最好,MedicalGPT-zh的次之,答题正确率为0.5,llama_7B_zh最差,正确率为0.1。
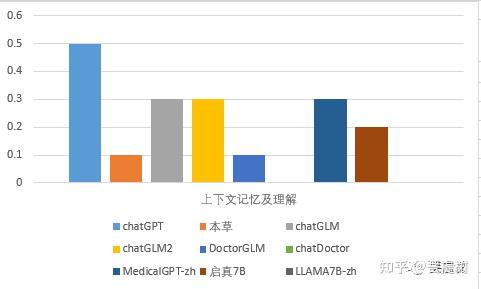
从上下文理解能力看,所有评测模型中,chatGPT得分率为0.5,其他模型上下文理解能力较差,最高得分率为0.3。其中chatGLM具备上下文理解能力,启真7B、MedicalGPT-zh响应时不会带入历史消息,不具备严格意义的上下文理解能力,部分题目中显示出来的上下文能力是基于大模型本身蕴含的知识。
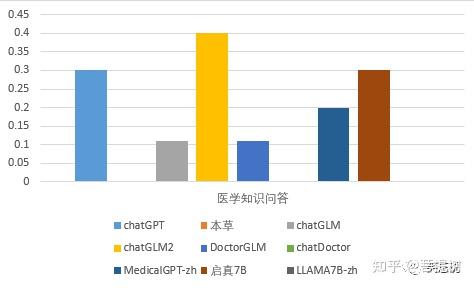
从医学知识问答的维度看,chatGLM2的表现最好,答题正确率为0.4,高于chatGPT得分,启真与chatGPT相当,chatDoctor、本草、Llama_7B最差,正确率为0。
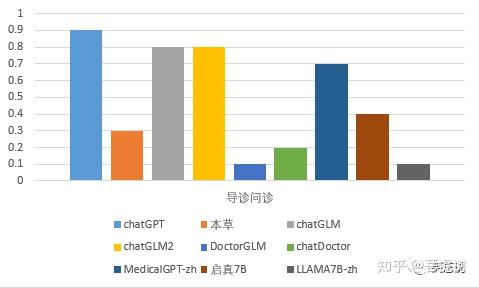
从导诊问诊的维度看,chatGPT的表现最好,答题正确率为0.9(也是所有评测模型所有能力中表现最好的一项),chatGLM_6B和chatGLM2_6B次之,正确率为0.8,DoctorGLM最差,正确率为0.1。
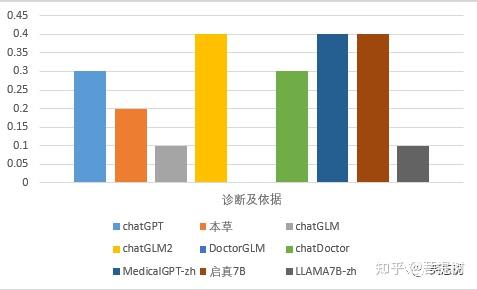
从诊断及依据的维度看,chatGLM2_6B、MedicalGPT-zh、启真7B的表现相近,也是当前最好的,答题正确率为0.4,优于chatGPT得分。DoctorGLM效果最差,正确率为0。

从疾病风险评估的维度看,chatGPT表现最好,chatGLM、chatGLM2、chatDoctor表现相近,正确率为0.3,DoctorGLM效果最差,正确率为0。疾病风险评估是大模型在医疗应用中安全性保障的重要内容之一,该维度中评测问题主要选择的是一些风险评判的标准,答案相对固定,但大多数的模型未能有很好的选择。

病历摘要总结的维度看,chatGLM2表现最好,chatGLM次之。特别说明,此处病历摘要选择GPT3.5产出的结果作为标准对比答案,该统计数据更多表明与GPT3.5相比,生成摘要的相似度,不一定能很好的说明真正的摘要总结能力。ChatGPT的得分为两次运行生成的不同回答,计算rouge-1中f值得分。 3.4 模型能力展示

ChatGPT在通用能力表现相对较好,医学能力上,医学知识问答和诊断依据较差,可能与题目设置有关,这两种类型题目类型差别不大,且需要大量专业的医学知识才能给出正确的诊断结果。 2. chatGML2

在所有评测模型中,除chatGPT之外,综合能力排第二。在中文语义理解、医学知识问答、诊断及依据、病历摘要总结方面超越chatGPT。
3. chatGML

在所有评测模型中,chatGLM在中文语义理解和病历摘要总结方面表现最佳。导诊问诊得分率为0.8,病历摘要总结得分为0.7,这两项内容均为大模型适合处理的任务,大模型内部蕴含的知识使得得分较高。由于chatGLM没有在医学能力专门微调,其他医学能力相对较弱。 4. MedicalGPT-zh

在所有评测模型中,Medical-zh在逻辑推理、安全和隐私、诊断和依据方面表现最佳。医学能力上,病历摘要总结能力在所有评测模型中排名第二,但是在疾病风险评估和医学知识问答方面比较弱势。 5. 启真

在所有评测模型中,启真与DoctorGLM和charDoctor表现相近,在逻辑推理方面最差。与chatGLM基模型相比,在传统医学任务诊断依据、疾病风险评估方面有一定提升。
6. chatDoctor

7. 本草
 8. DoctorGLM

整体表现很差,最好的能力得分率不足0.4。医学能力检测上,在逻辑推理、数据抽取和格式输出、诊断和依据、疾病风险评估4各维度没有得分。该模型对输入理解很差,几乎不能理解输入的指令,答题结果倾向于对输入内容续写,而不是完成指定任务。 3.4.9 Llama7b-chinese

llama7B-chinese在所有评测模型中综合表现最差,在多个维度得分为0。得分最高的维度为0.2。不具备理解输入指令的能力,只会在输入文本的基础上进行文字续写。
4 总结
- 从整体表现看,ChatGPT综合能力最强,尤其在隐私数据安全方面遥遥领先。生成内容安全无害、能够保护隐私是大模型最具挑战性的能力之一,也是大模型能否商用的挑战之一,显然,chatGPT在这方面做了很多工作。此外,chatGPT模型参数较多,也符合大家预期的参数量较大时模型各方面综合能力往往更好。
- 通用能力上,除中文语义理解外,ChatGPT效果最好,其次同为底座模型的ChatGLM2,chatGLM次之。
- 在医学能力上,ChatGLM2效果最好,其次为ChatGPT。
- DoctorGLM和Llama7B-chinese表现最差。这些模型理解输入指令的效果最差,无法根据Prompt完成任务,总是基于输入内容续写后续可能出现的内容。
| 



 发表于:
发表于: